
Data Science – the term is everywhere and for a good reason. With more and more data being generated every minute, it is imperative that companies adopt technologies like data science to store, process, and analyze that data. Everyone uses the term, but how many actually know its meaning and definition?
Data Science basics
Data science can mean different things to different organizations, and can even vary from person to person. It is a fast-evolving field that has an enormous range of applications. In its most basic form, data science is the study of data. More specifically, it is the study of methods to extract useful information and insights from data using computers. At its core, data science produces insights.
While insights alone can be extremely helpful, data scientists also employ tools to predict outcomes using those insights. They do this using machine learning. Machine learning gives computers a framework to do what comes naturally to humans: learn from experience. A machine learning algorithm, which relies on patterns and inference to “learn,” can be used to generate predictions about future behavior. A machine learning model is an algorithm that ingests data, finds patterns in that data, and produces a prediction.
So, what do all these Data Scientists actually do?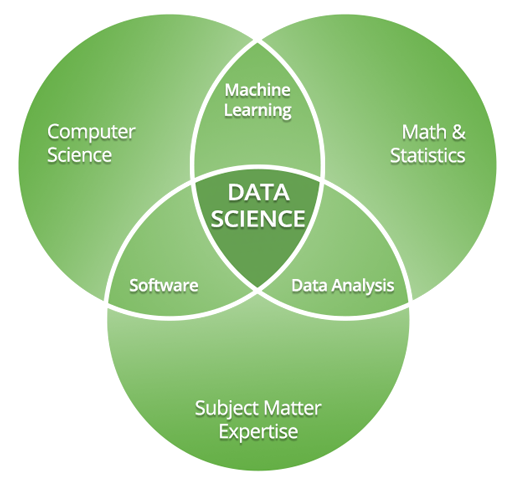
Data scientists write code to organize, analyze, and present data. They do this using methods from data science and machine learning. Therefore, good data scientists must have an understanding of statistics, computer science, and business trends. Since nobody can be that good at everything, the best data science teams also employ subject matter experts (SMEs).
Let’s break down these core data science tasks – organizing and analyzing data – in more detail.
Organizing data (aka data wrangling)
Perhaps the most time-consuming part of being a data scientist is organizing data. While data collection is becoming more ubiquitous, unfortunately, most of this data is not “machine learning ready.” Since machine learning models rely on patterns and inference to “learn,” the data must be representative of the real-world problems the model will encounter. Learn more about “garbage in, garbage out” as it relates to frac data here.
Manipulating data so that it reasonably represents the real-world is not an easy task. This requires not only a thorough understanding of the data (hey there, SMEs!) but also the ability to think through what new problems the model will likely encounter. Depending on the data, engineering new features, or feature engineering, can improve the performance of machine learning models.
One example of an engineered feature is shown on the right. Using the pressure channel, we are able to engineer a new feature – the first derivative of the pressure. Since the first derivative contains information about the shape of a signal, it is a useful feature in signal processing (frac data, at its core, is just a collection of signals that change over time).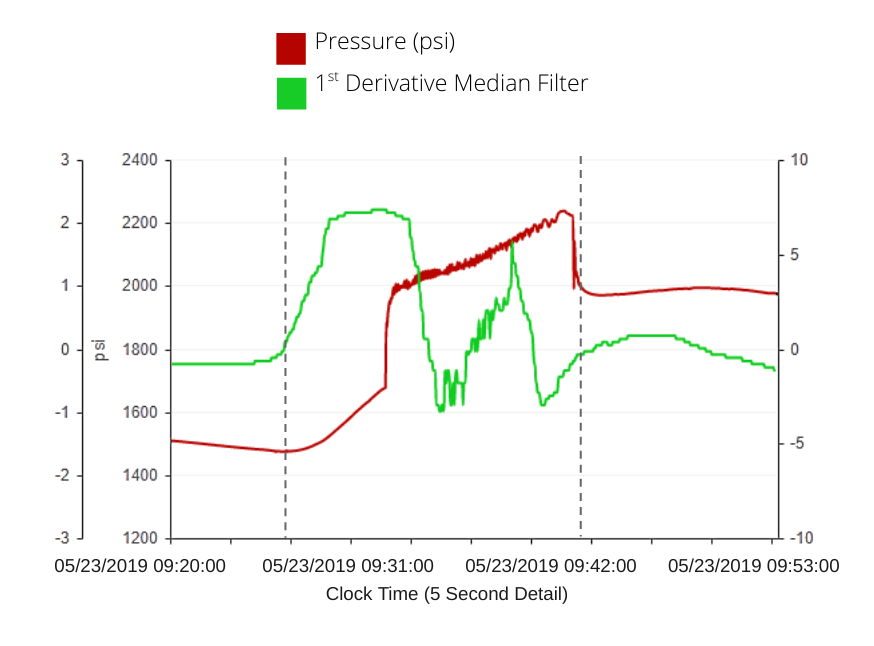
When done well, feature engineering is the most powerful method to improve the performance of a machine learning model. However, engineering too many features without real-world application results in a large volume of data that may not be insightful. As with everything, strike a balance.
Analyzing data (aka what do I do with all of this data?)
Once the data is organized and cleaned, useful information can be extracted using data analytics and machine learning. A good data scientist will clearly outline what kinds of projects are realistic and within the scope of the data provided. Gathering insights about historical data using data analytics techniques is often faster and more efficient than a full-scale machine learning approach.
However, if the data is sufficient in size and cleanliness, machine learning is a powerful tool that can be used to generate predictions on novel data. Building a machine learning model can be broken down into two steps – choosing an algorithm, and using that algorithm to train a model.
Choosing the correct algorithm depends entirely on the problem at hand. For instance, a regression problem requires a regression algorithm. In fact, if you’ve ever taken algebra, you’ve likely used a simple regression algorithm. Linear regression, or the process of fitting a line to data, can be categorized as a machine learning algorithm. Other algorithms can be found online in open-source libraries (we use Python at WDL), or they can be implemented from scratch. Here is a wonderful cheat sheet that illustrates some of the options available.
Once an algorithm is chosen, it can be “trained.” The process of training an algorithm allows it to find patterns in the data and associate those patterns with the desired prediction. The output of this process is known as a machine learning model. Again, if you’ve ever performed a regression by fitting a line to predict the value of y for a given value of x, you’ve trained a model.
Now your model, which at its core is just an algorithm that ingests data and is trained to find patterns in that data, is ready to produce predictions.
Stay tuned for more – the next post will cover how data science translates to ROI for completions data.